k-Nearest-Neighbours Classification under Non-Volatile Memory Constraints
A k-Nearest-Neighbour (kNN) classifier is a non-parametric type of classifier, which predicts the class of unseen examples based on their Euclidean distance from known examples stored in non-volatile memory. Because of its non-parametric nature, its training phase consists of just a mere storage operation. In contrast to other classifiers, there is no need for a computationally expensive parameter update process. This characteristic makes kNN classification a suitable candidate for learning from the data stored in the non-volatile memory of a microcontroller system, whose resources are heavily constrained.
The goal of this mini-project was to evaluate the baseline classification accuracy that a kNN classifier can obtain on toy datasets such as MNIST and Fashion-MNIST, when trained in binary classification and class-incremental scenarios under the non-volatile memory constraints of a few MBs. To limit the scope of the experiments, no constraints were placed on volatile/working memory. The experiments were implemented in Python and run on the High performance Computing facility offered by the University of Southampton. They were intended to serve as a proxy for a memory-constrained embedded system.
Experiment 1
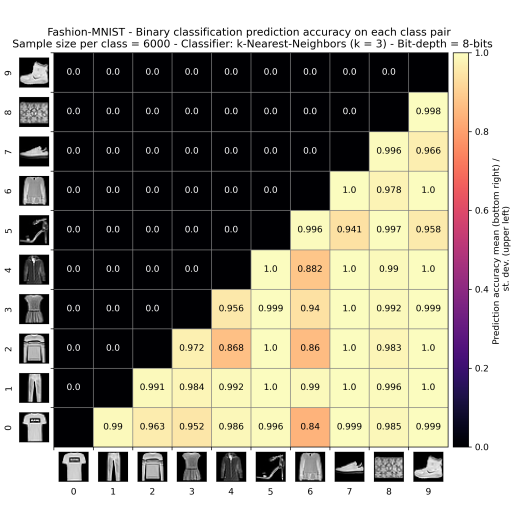
The role of the first experiment was exploratory. Its aim was to evaluate the prediction accuracy of the kNN classifier when trained for a binary classification task on examples from all possible pairs of classes of the chosen dataset under memory constraints. It was expected that due to the similarity in the training examples from certain pairs of classes (i.e. "pullover" and "coat" classes from Fashion-MNIST), the classifier's ability to separate them would be reduced.
To introduce memory-constraints, a random sample of training examples from each class was selected to form the training set. The size of the random sample was the same for both classes and it was varied to evaluate how the classifier's accuracy is affected by the total number of training examples. It was expected that when the size of the sample was set equal to the number of available examples for each class (the sample was the full set), maximum prediction accuracy would be achieved. The prediction accuracy was evaluated on all the test examples available to the pair of classes.
To account for the stochasticity of the random samples, the experiment was repeated 10 times for each pair of classes and sample size. At every iteration, a new random sample was used for each class. At the end of the 10 iterations, the mean and the standard deviation of the prediction accuracy obtained at each iteration were calculated.
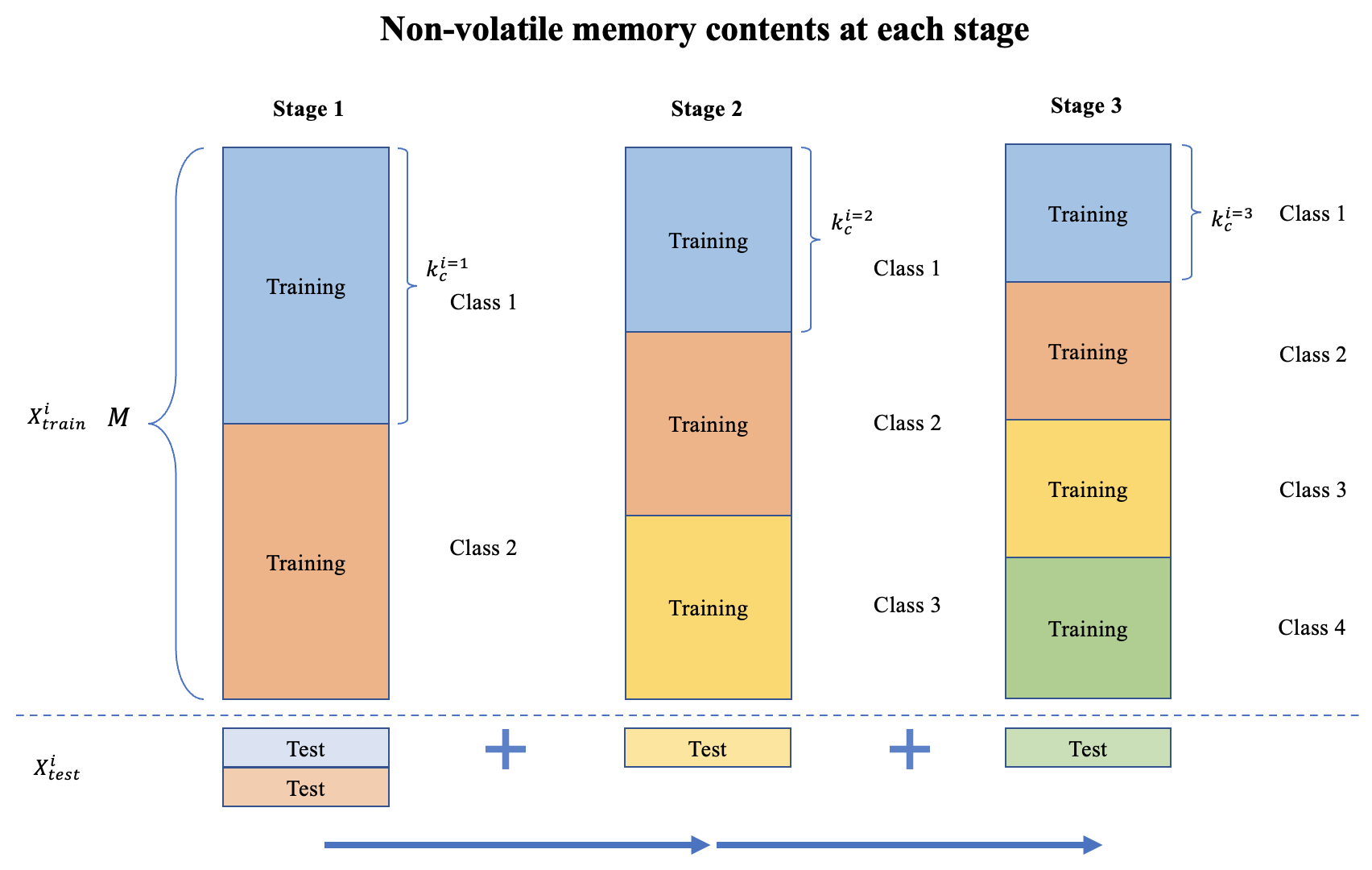
The results of the experiment were presented in the form of prediction accuracy heat-maps. Each of them was generated for a specific sample size. The heat-map shows the mean and the standard deviation of the prediction accuracy obtained for every pair of classes after 10 iterations. Class pairs with the lowest mean prediction accuracy are the ones that exhibit the highest similarity.
The identification of class pairs with a high degree of similarity acts as a tool for analysing the variations in the classifier's prediction accuracy in the class-incremental scenario tested in Experiment 2.
Figure 1 shows the accuracy heathmap generated for the Fashion-MNIST dataset without any random sampling.
Experiment 2
Experiment 2 was designed with the aim of capturing the effect of incrementing the number of classes present within the classifier's train set on the classifier's prediction accuracy. Starting from just 2 classes, which is equivalent to the binary classification task from Experiment 1, the number of classes is increased by a single class at each stage of the experiment.
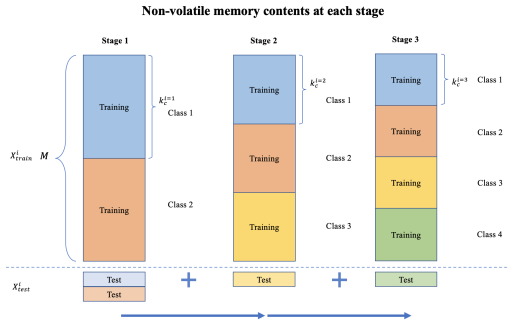
Memory constraints were introduced by specifying a limit on the number of total training examples that can be stored within the classifier's non-volatile memory. The size M of the non-volatile memory is set to a fixed number of bytes. Then, depending on the total size s of each training example (data + label), the maximum number of examples k that can fit in non-volatile memory is calculated.
The memory is equally split between the examples from each class. Given the fact that not all examples available to each class might be able to fit, a random sample of examples will have to be generated. After the classifier's prediction accuracy has been evaluated, examples from each class are randomly dropped to make some space for examples from the new class. As in Experiment 1, prediction accuracy is evaluated on all the available test examples from the classes present at the current stage.
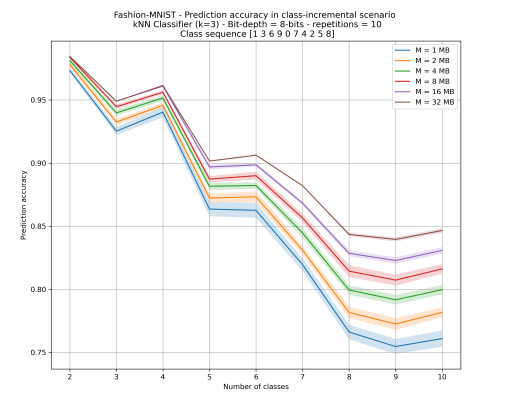
The experiment is repeated for multiple values of M and multiple class sequences (because of the combinatorial explosion, it is not feasible to repeat the experiment for every possible sequence). For every combination of M and class sequence, the mean and standard deviation of the prediction accuracy at each stage is calculated over 10 iterations. The calculated accuracy values were used to create plots showing how accuracy changes from one stage to the other because of the introduction a new class.
It is expected that when a new class, which is highly similar to one or more classes already present in the classifier's memory, is introduced to the classifier, prediction accuracy will be reduced. However, if a new class that shows little or no resemblance to any of the present classes, accuracy will be increased. It is also expected that at the final stage of the experiment, when examples from all classes are present in the classifier's memory, the prediction accuracy should always converge to the same value, with some variation allowed because of the random sampling.
Figure 2 shows how the contents of the non-volatile memory are changed at every stage of the experiment. In Figure 3, the prediction accuracy obtained for different non-volatile memory sizes at each stage of the experiment is presented for a specific class sequence.
 Epifanios Baikas
Epifanios Baikas
PhD Student
at University of Southampton
Research area: Machine Learning on Resource-Constrained Embedded Systems
![]() Firmware
Firmware
Submitted on
Add new comment
To post a comment on this article, please log in to your account. New users can create an account.