Competition 2025
Competition: Hardware Implementation
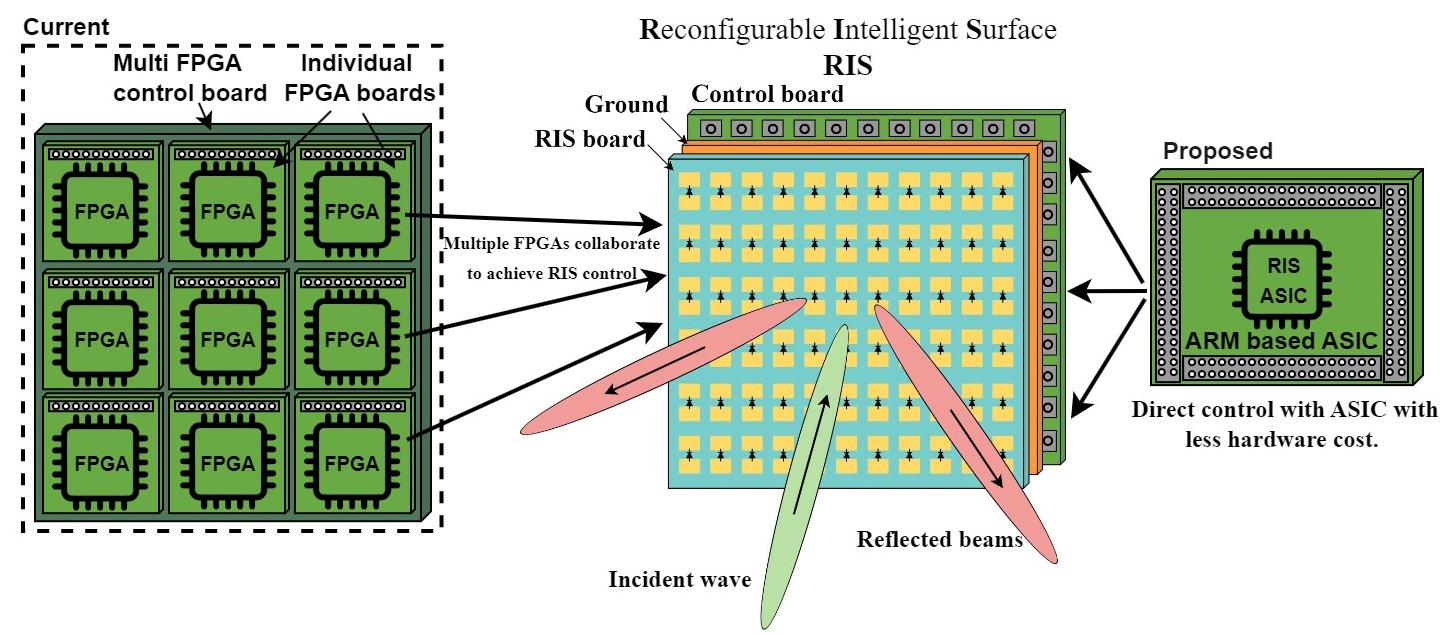
Reconfigurable Intelligent Surfaces (RIS) are planar structures composed of large arrays of tunable elements that can dynamically redirect, reflect, or shape wireless signals in the environment.
 Zhicheng Shen
Zhicheng Shen


 Fidel Makatia
Fidel Makatia
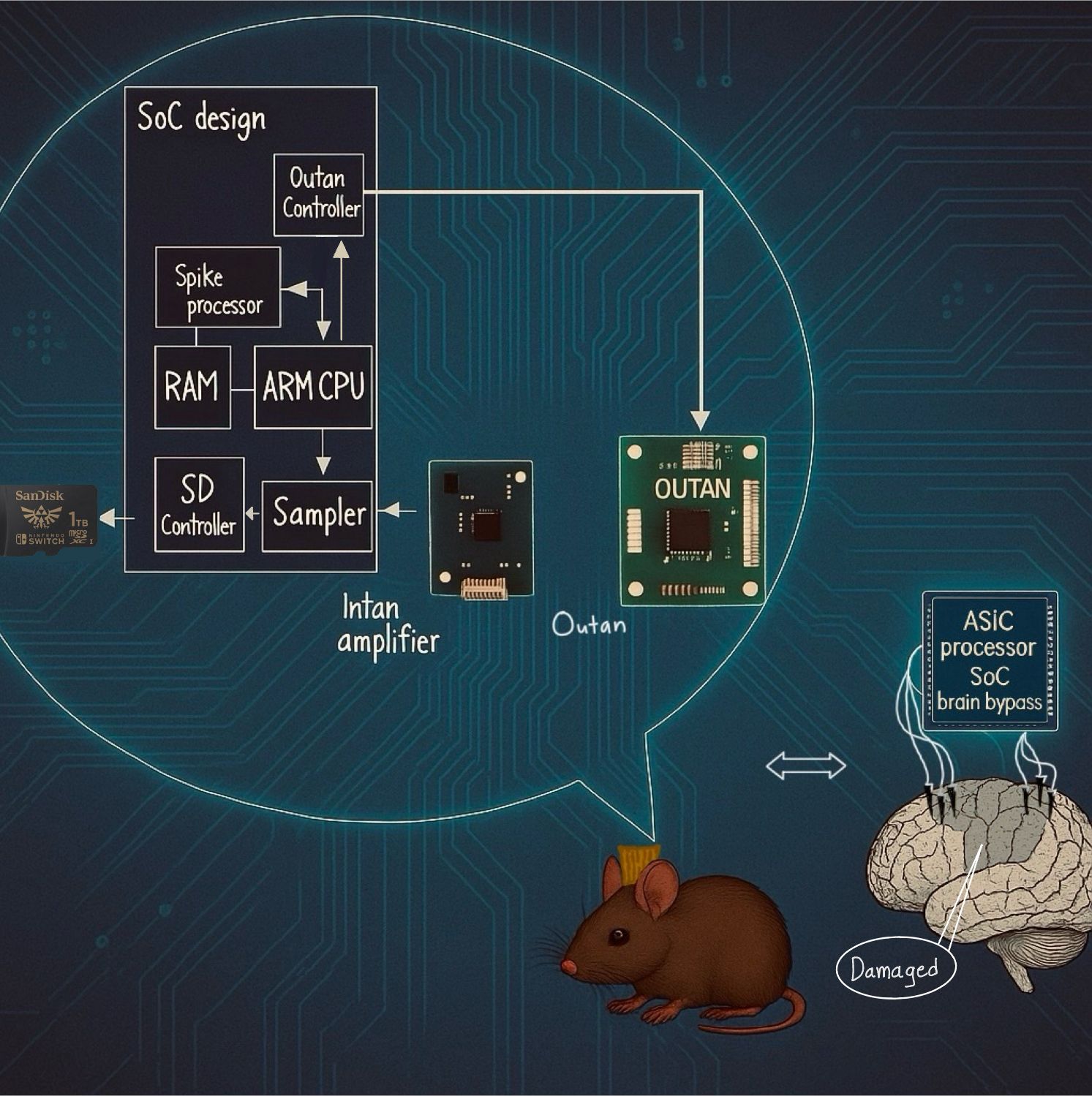

 The Anh Nguyen
The Anh Nguyen


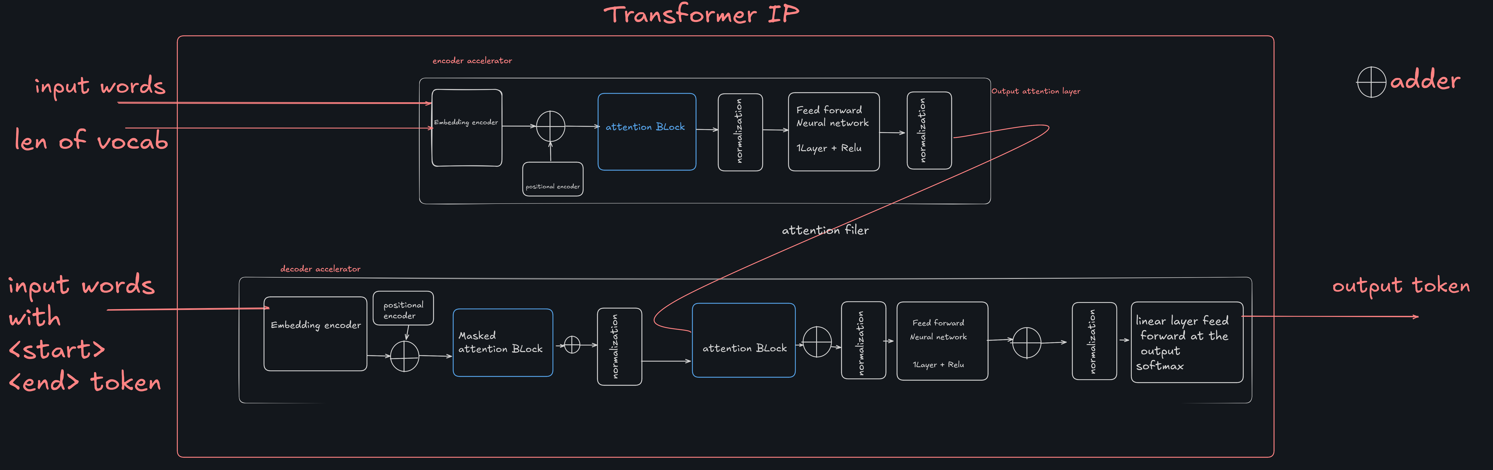

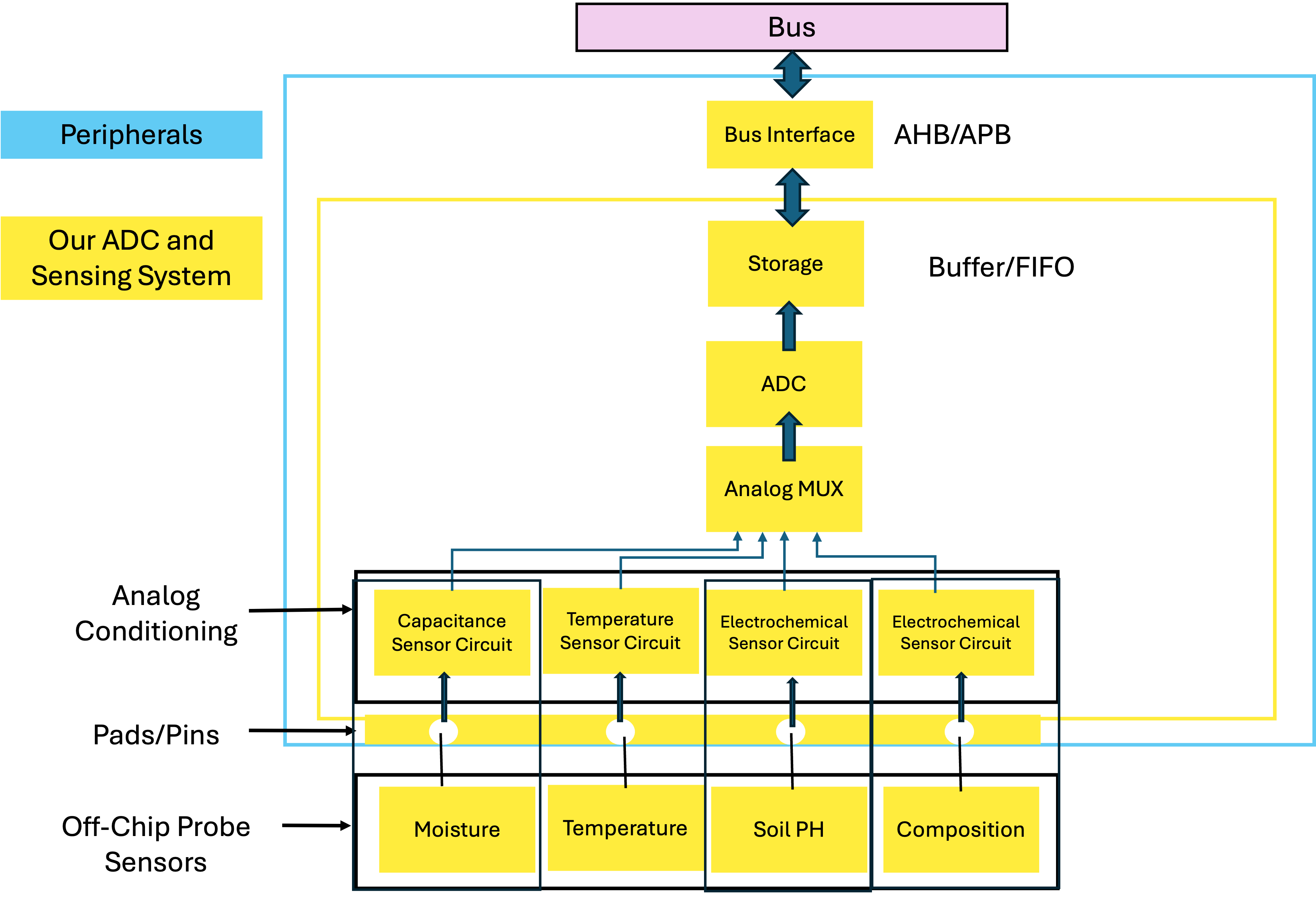

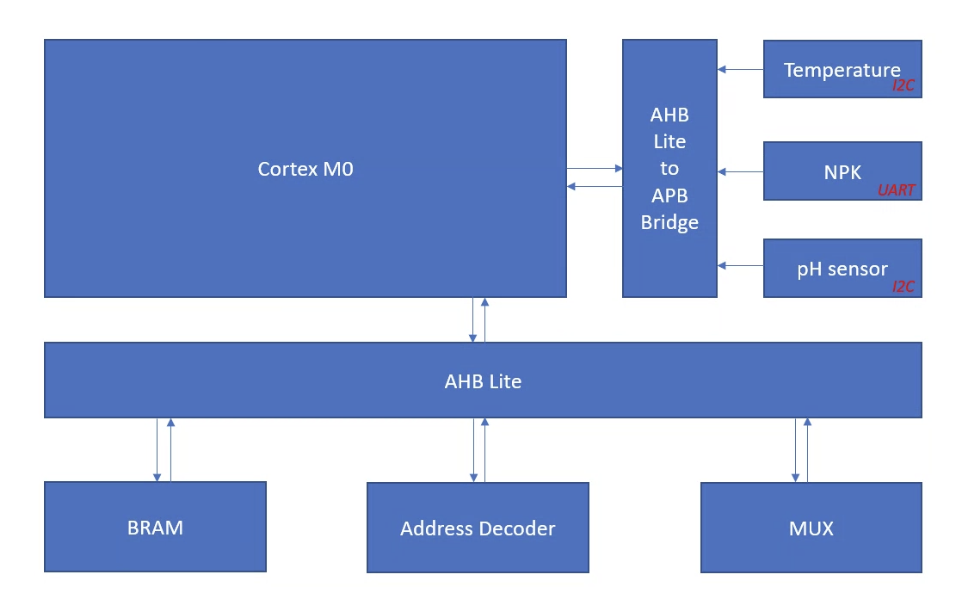

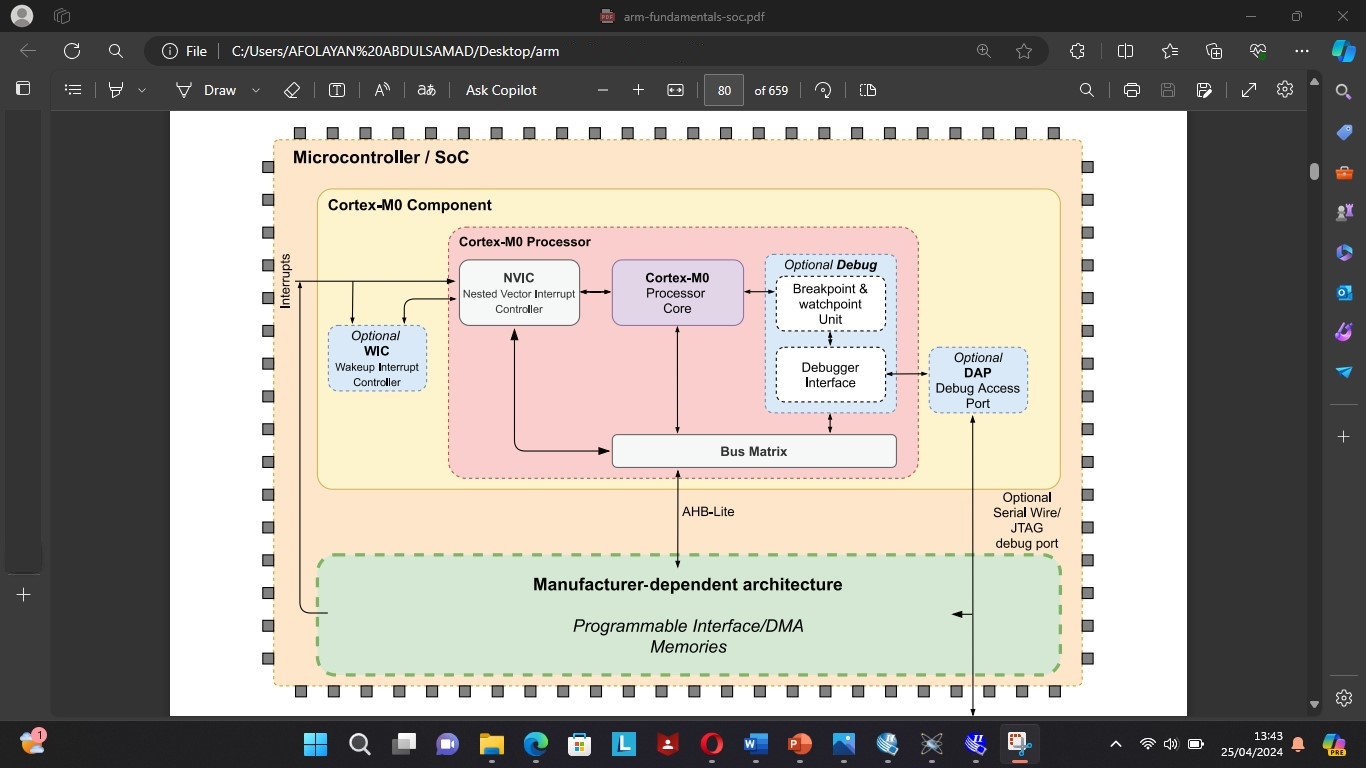

 AFOLAYAN, ABDULSAMAD
AFOLAYAN, ABDULSAMAD