PyTorch
PyTorch is a popular library used for Artificial Intelligence / Machine Learning ("AI/ML") development among the academic community. Like any library, it offers abstractions that allow designers to develop solutions using high level primitives, hiding lower level considerations such as physical memory management.
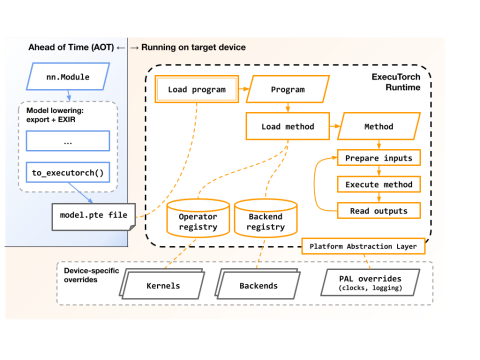
ExecuTorch is a portable runtime for executing models on compute infrastructures. Like it's peer, LiteRT (new name for TensorFlow Lite within the TensorFlow library system) it provides a unified way to access either portable versions of kernels or platform optimised versions of kernels including custom acceleration.
The PyTorch library provides a method (torch.export) to export a portable representation of the execution of a model as a graph expressed in terms of operators, etc. The graph goes through a compilation process which translates towards the target compute infrastructure. This can involve steps such as quantisation and subgraph reductions such as pruning.
The ExecuTorch runtime has responsibility for mapping the operators in the execution graph to the target compute implementation. It uses a registry of available targets to make the mapping. This is implemented as a set of function pointers to kernels to keep execution overhead low. It also offers methods to manage memory allocation for constant and variable model data.
Compute infrastructure providers such as Arm provide 'backend delegates' that allow the ExecuTorch runtime to map the portable graph for efficient execution.


Add new comment
To post a comment on this article, please log in to your account. New users can create an account.