Efficient Keyword-Spotting on an Arm M7 microcontroller
Project background
The presented work was part of the MIND6003 Interdisciplinary Team Project where a team of 1st year PhD students from MINDS CDT (University of Southampton, ECS) worked in collaboration to address a practical, real-world problem over a period of 18 weeks.
Motivation
The computational and memory requirements of state-of-the-art neural networks are usually considered the primary concerns when deploying them on resource-constrained edge devices. The limited energy budget, under which these devices have to frequently operate, introduces the need of estimating the amount of energy required per inference from these models. The aim of this project was to extend existing work in the field of Keyword-Spotting on Arm microcontrollers presented in Hello Edge: Keyword Spotting on Microcontrollers by capturing real-life energy measurements per inference.
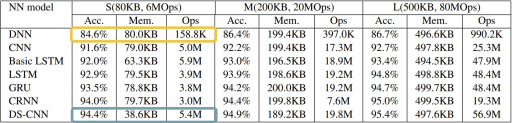
The types of neural networks for which energy measurements were captured were a standard Multi-Layer Perceptron (MLP) and a depthwise-separable CNN. Both networks were trained on Google's Speech Command Dataset developed specifically for Keyword-Spotting applications. The motivation behind experimenting with these two types of networks specifically was their considerable differences in the memory footprint and number of operations required per inference (Table 1)
Keyword-Spotting
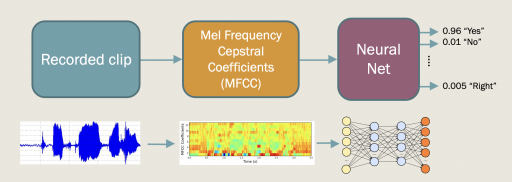
The implemented Keyword-Spotting algorithm can be separated into two distinct parts. The first one is responsible for creating a perceptually relevant feature map by extracting the Mel-Frequency Cepstral Coefficients (MFCC) from the recorded audio clip. The MFCC extraction process involves splitting the time-domain signal into overlapping windows and applying a series of signal-processing operations on them (Figure 1). The extracted feature map is then used as an input to the classification networks (Figure 2).

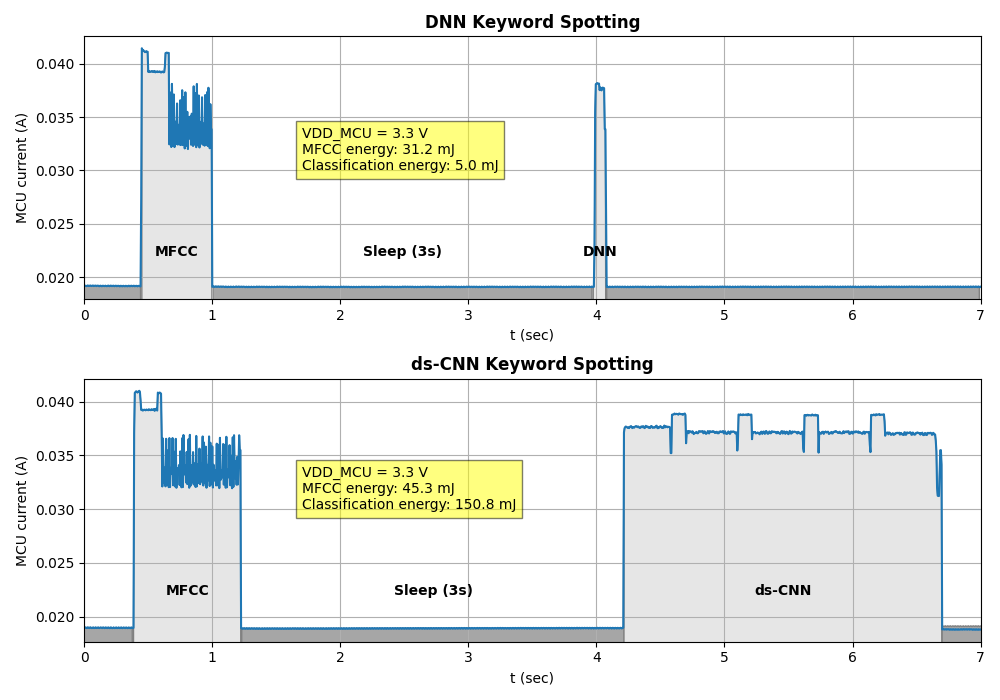
Results
The measurements showed that the energy required per classification from the ds-CNN was approximately 30x higher than that required by the MLP. An important observation was that the Mel-Frequency Cepstral Coefficients (MFCC) calculation introduces a considerable energy overhead independently of the choice of neural network.
Measurements were obtained by deploying the models on an STM32 F756ZG Nucleo board. A demo Keyword-Spotting application was developed for the STM32 F769I Discovery Board. Project code and energy measurements can be found at the project's GitLab repository.
Team




 Epifanios Baikas
Epifanios Baikas
PhD Student
at University of Southampton
Research area: Machine Learning on Resource-Constrained Embedded Systems
 Cortex-M7
Cortex-M7
![]() Firmware
Firmware
Submitted on
Comments
Similar work
Some interesting parallel work is presented here by Michele Magno from ETH Zurich.
tinyML Talks - Michele Magno: LW Embedded Gesture Recognition Using Novel Short-Range Radar Sensors - YouTube
The same areas of concern, feature extraction, choice and model optimisation, etc. A variation of the input medium but target similar application in terms of human to machine interaction. Some investigation on the Arm M7 microcontroller as well as alternative hardware.
Similar work
Thank you for the comment, there are indeed some common steps in the inference pipeline used for both keyword-spotting recognition and hand gesture detection. However, from the results presented around 21:33 in the video, it looks like the feature extraction stage for gesture recognition (just an FFT) consumes a relatively small amount of energy when compared to the energy consumed by the rest of the stages. In the case of keyword-spotting, the feature extraction consumed a relatively high portion of the overall energy, which can be attributed to the several processing steps required for extracting the MFCC coefficients. The selection of a Temporal Convolutional Network as the model architecture is an interesting one and it would be worth testing whether there is any benefit in adopting that architecture for keyword-spotting applications.
Add new comment
To post a comment on this article, please log in to your account. New users can create an account.