TensorFlow

TensorFlow is one of a number of environments to build and deploy ML models. TensorFlow offers multiple levels of abstraction to allow model designers to be removed from specific choices of description language or hardware platform.
To deploy ML models on System on Chip design usually requires constraint of the model to fits with the constraints of the hardware resources available. TensorFlow Lite or LiteRT is a specific runtime implementation of a limited subset of TensorFlow operations suitable for inference on mobile and edge devices. It is a portable C++ library for 32-bit platforms.
The portable reference kernels implemented in C/C++ also have platform specific hardware optimised versions. For the Arm ecosystem a set of kernels are optimised with Arm's CMSIS-NN library.
The following steps are required to develop and deploy a TensorFlow model on a microcontroller:
- Training: Generate a small TensorFlow model that can fit the target device and contains supported LiteRT operations.
- Convert to a LiteRT model using the LiteRT converter.
- Convert the model to a C byte array using standard tools to store it in memory on the device.
- Run inference on device using the LiteRT library kernels.
Below is a list of the LiteRT library kernels with CMSIS-NN library optimisations.
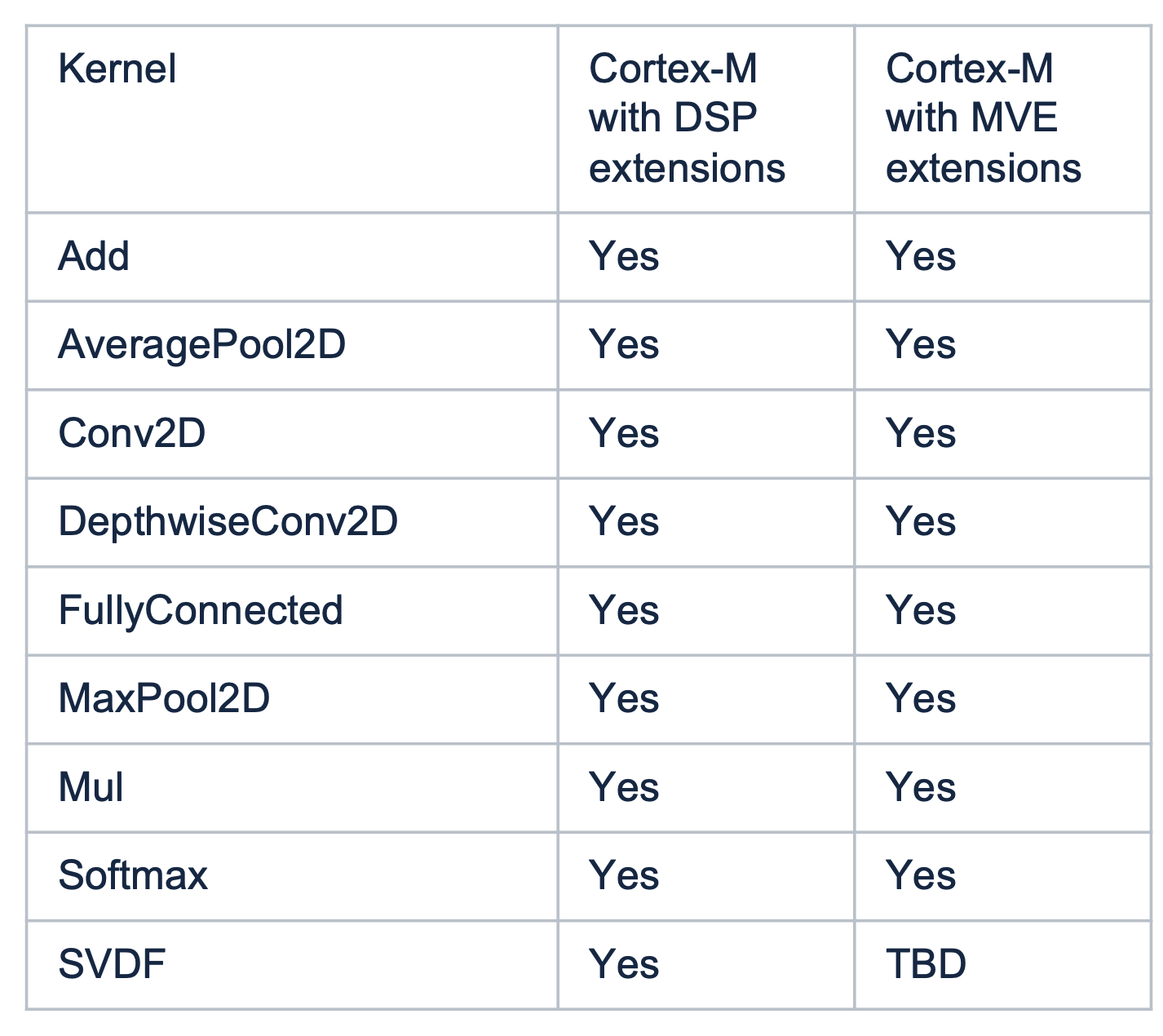
Source: TensorFlow community post on TensorFlow Lite for Microcontrollers and CMSIS-NN
Most of the optimizations are implemented specifically for 8-bit quantized (int8) operations which is one option for model compression and pruning in order to reduce compute intensity as well as memory overhead. The challenge is to compress the model to decrease the memory size and system data movement with minimal accuracy loss.
By default, LiteRT provides kernels that execute on the Arm CPU. LiteRT Delegates enable hardware acceleration of LiteRT models by leveraging on-device accelerators. There have been a number of projects looking to develop custom acceleration of TensorFlow Lite kernels that are suited to particular types of Machine Learning models.
LiteRT have an Inference Diff tool to help compare execution (in terms of latency & output-value deviation) for CPU based inference to a user-defined inference.
The nanoSoC reference design provides a simple Arm Cortex-M0 microcontroller SoC to support the development and evaluation of research components or subsystems including custom accelerators. The Arm Cortex-M0 has a small instruction set, simple 3-stage pipeline and 32-bit registers. Most instructions generated by the C compiler use the 16-bit instructions for increased code density.
The nanoSoC supports offload of inference tasks from the CPU to accelerator hardware that can be customised to the specific model if required.
In CPU based inference the model is converted to a C byte array. This allows the model to be brought into the CPUs arithmetic logic via the normal process of executing instructions for addition, subtraction and multiplication.
In nanoSoC with a custom accelerator the model is passed through the accelerator by DMA engines that offload the work from the CPU. The model, stored can be stored in on-chip memory and moved efficiently across the AMBA bus for use in the custom accelerator.

Comments
Support for the Ethos U55
The Vela compiler is a tool to further optimise a TensorFlow LiteRT model to be accelerated by the arm Ethos-U microNPU. The compilation uses custom operators for parts of the model that can be accelerated by the Ethos-U microNPU. Parts cannot be accelerated are left unchanged for execution on the CPU.
Copyright © 1995-2024 Arm Limited (or its affiliates). All rights reserved.
It supports quantization to either 8-bit or 16-bit (signed). The compilation can be configured to suite the specific hardware instantiation of Ethos hardware, adjusting properties like memory locations, latencies and bandwidths. The compiler works in coordination with a runtime driver to control which AXI ports to use for memory data access for the model.
Add new comment
To post a comment on this article, please log in to your account. New users can create an account.