
Projects
Articles
Interests
Design Flow
Technology
Authored Comments
| Subject | Comment | Link to Comment |
|---|---|---|
| Verification Methodology |
Hi, just added a comment on Todays call: High Capacity Memory Subsystem Development | SoC Labs In it 'A discussion on the verification strategy occurred and we agreed that the second meeting in December would be dedicated the verification'. Do you think you can get involved with this and help determine the verification planning for the project? We look forward to hearing from you. |
view |
| Sizing potential system design to natural languages models. |
It was good to have the call today and discuss the project. It was helpful to discuss the specification for the project as well as progress on the development of your model and activities to reduce the size of the model for inference on the edge. As we discussed the small microprocessor SoC reference design such as nanoSoC are perhaps capable of keyword detection tasks with a mid-range SoC reference design using specific acceleration subsystem can handle more demanding speech recognition tasks. Hopefully this diagram from the ML Developers Guide for Cortex-M Processors and Ethos-U NPU is helpful in visualising the types of ML application.
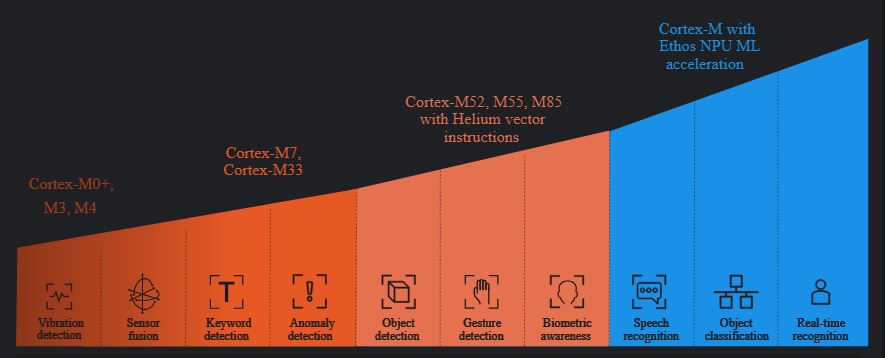 Copyright © 1995-2024 Arm Limited (or its affiliates). All rights reserved As we discussed it is not only the computational intensity of the specific ML application but the size of the model and movement of data representing the model within the system both the System on Chip memory and the external off chip memory demand. |
view |
| Larger language models |
We also discussed the option for deploying the model on the Corstone 300 Fixed Virtual Platform with the ability to separate parts of the model compute to the Ethos-U NPU or the M class CPU in an optimal way. 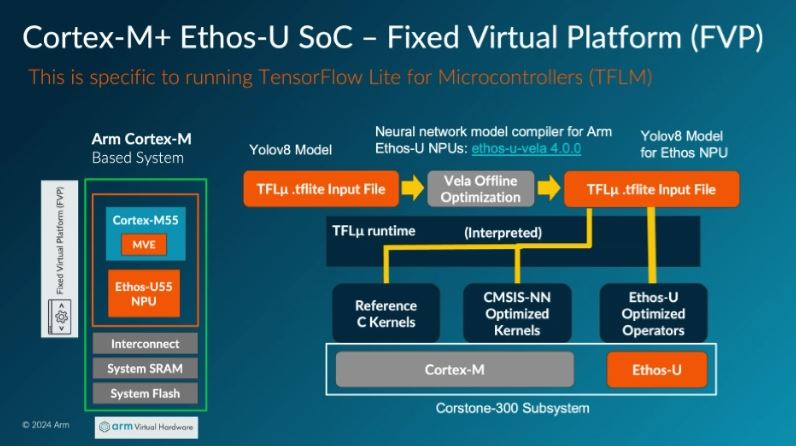
LiteRT is the new name for TensorFlow Lite (TFLite) which is a portable runtime for executing models from a number of AI/ML frameworks including TensorFlow. Without optimisation the runtime would use portable Reference C Kernels. Arm provides kernels optimised for it's processors in the CMSIS-NN library. Some operations can be highly optimised by execution within the Ethos-U accelerator. Velo takes a portable model and changes it to request the runtime to use the most efficient Arm compute infrastructure. A baseline might be established by taking your model and seeing if it can be effectively executed on the M55/U55 combination using a Fixed Virtual Platform as a simulation environment. |
view |
| Generating ASIC implementation from HLS4ML |
In this interesting Siemens EDA presentation on Catapult + HLS4ML for Inference at the Edge it is clearly shown why generating the right intermediate code is important to allow efficient ASIC implementation. 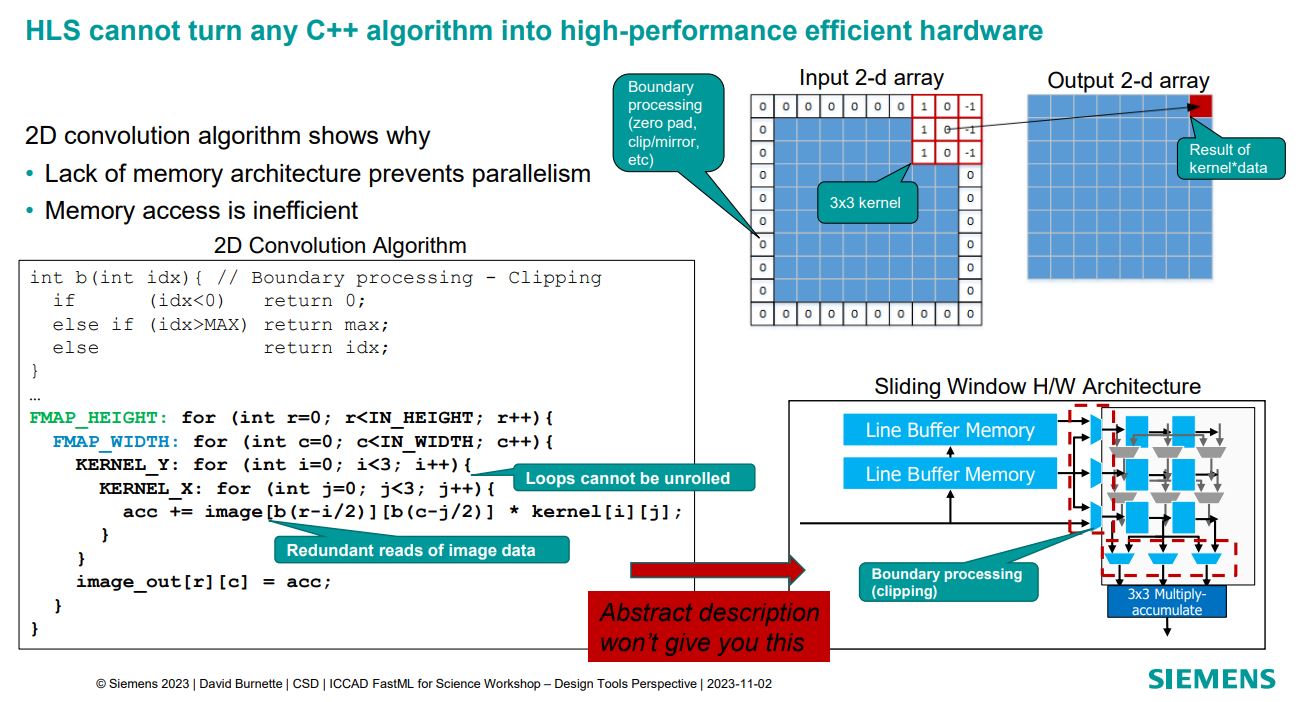 David Burnette in this presentation illustrates a hardware design pattern, Sliding Window, and how generating the appropriate code from the HLS4ML environment allows the design pattern to be used to make an efficient implementation. 
|
view |
| Update as of end of November |
Perhaps a Milestone 14 could be added? Now that Europractice have set out their schedule for 2025 fabrication shuttles then the 16th April mini@sic shuttle looks a good candidate for a nanoSoC version 2 tape out. 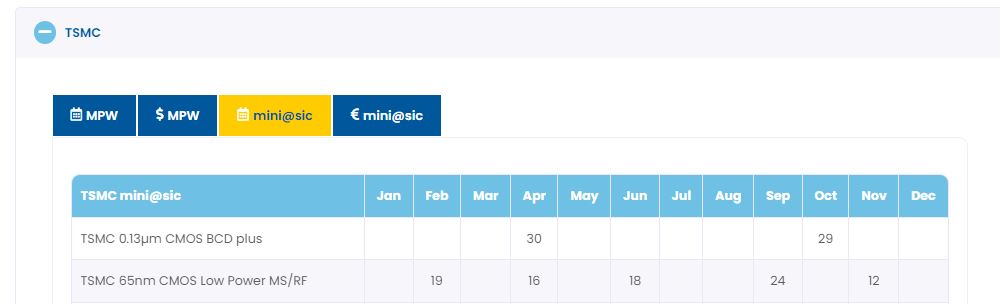
Is there a Milestone for the implementation of the Hyperbolic tangent and sigmoid functions ? When will this be complete? |
view |
| Data transfers and Firmware |
Looking at this diagram from the ML Developers Guide for Cortex-M Processors and Ethos-U NPU your application is in the vibration detection class I suspect. As you are planning on using DMA then the M0 processor will handle the data movement through your custom accelerator. 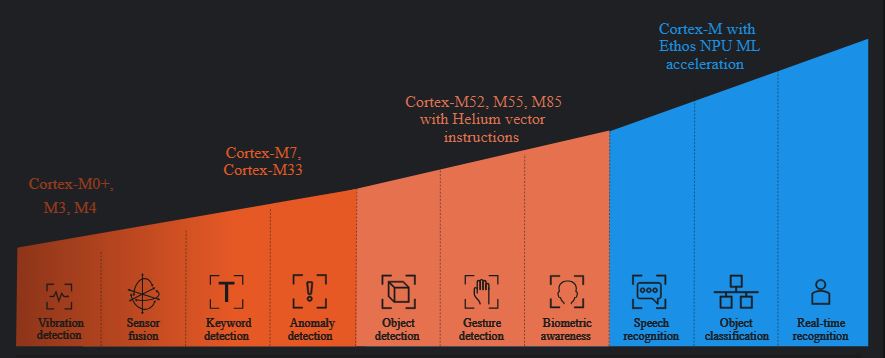 Copyright © 1995-2024 Arm Limited (or its affiliates). All rights reserved I recently updated the Interest on Firmware. I suspect you will need to develop a device driver for your custom accelerator to handle the interactions and interrupts. |
view |
| Welcome to SoC Labs |
Hi, It would be great if you could let us know your interest in SoC Design and then we can help collaborate on any potential project. We look forward to hearing from you. |
view |
| Welcome to SoC Labs |
Hi, Thank you for joining SoC Labs. Your profile says you are a student. I think you may be studying for a Masters at Illinois Institute of Technology. Is that correct? We look forward to hearing from you. |
view |
| Welcome to SoC Labs |
Hi, Thank you for joining SoC Labs. Your profile says you are a student. I think you might be studying at Georgia Institute of Technology. Is that correct? We look forward to hearing from you. |
view |
| Code reading and Comments |
I must draw the attention of the team to the quality of comments Angelo has put in the UberDDR3 project. It is an example to all to follow. 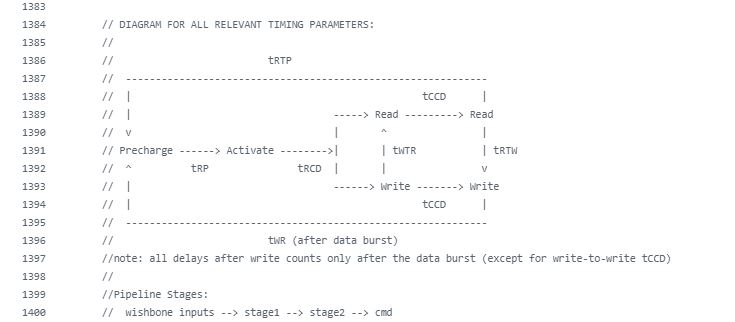
|
view |
Comments
Hi John,Thank you so much…
Hi John,
Thank you so much for the warm welcome to the community. Sure I would love to learn more. We can have a meeting at your convenience and discuss it. Let me know which times and dates work for you.
Add new comment
To post a comment on this article, please log in to your account. New users can create an account.