A 28nm Motion-Control SoC with ARM Cortex-M3 MCU for Autonomous Mobile Robots
Autonomous mobile robots (AMRs) have been proven useful for smart factories and have the potential to revolutionize critical missions, such as disaster rescue. AMRs can perceive the environment, plan for assigned tasks, and act on the plan. Motion control is critical to the robot's action, which is accomplished through trajectory optimization to refine the robot's states using a physics model. However, the high computational complexity of trajectory optimization poses significant challenges for AMRs with limited power and computing resources. In addition, the computations of trajectory optimization are adapted to the physical configurations of AMRs, requiring the underlying computing resources to be flexible enough while maintaining high efficiency.
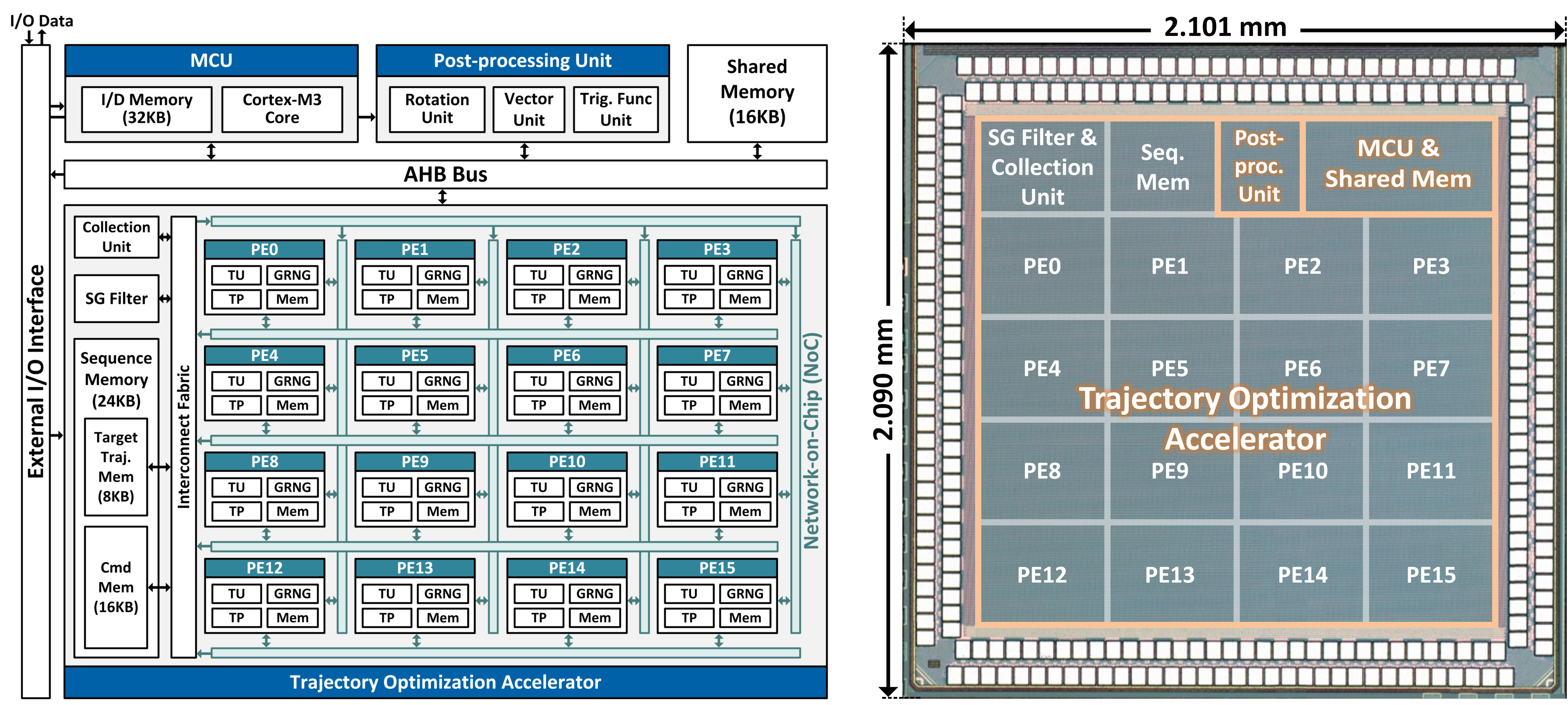
To address these challenges, this work proposes a prototype of motion-control SoC that perform low-latency, energy-efficient trajectory optimization while supporting various AMR configurations. The SoC includes an ARM Cortex-M3 MCU, a trajectory optimization accelerator, and a post-processing unit. The trajectory optimization accelerator leverages parallelism in the trajectory optimization algorithm. It contains a 4x4 array of processing elements that compute in parallel to reduce the trajectory optimization latency. The ARM Cortex-M3 MCU is programmed by software for flexible system configurations, scheduling, and auxiliary data processing.
The SoC is implemented through the cell-based ASIC design flow. The ARM Cortex-M3 MCU and the AHB bus infrastructure are synthesized using the open-source RTL implementation, and other parts of the SoC are designed in-house. The software programs for the MCU are compiled by the ARM GNU toolchain. Fabricated in 28nm CMOS technology, the motion-control SoC integrates 5.3M logic gates and 146KB on-chip SRAMs in a core area of 3.56mm2. The SoC dissipates 142mW at a 200MHz clock frequency from a 1.0V supply. The chip achieves a 4.935kHz maximum control rate for a 7-Degree-of-Freedom robot arm. Compared to the state-of-the-art motion-control accelerator, this work achieves a 22× improvement in the maximum control rate. It also delivers 350× higher energy efficiency, despite the added flexibility. This prototype demonstrates a promising solution for future agile humanoid robots that require ultra-fast response and robust control.
Project Milestones
Do you want to view information on how to complete the work stage ""
or update the work stage for this project?
-
Milestone #1
Target Date -
Milestone #2
Target Date -
Milestone #3
Target Date -
Milestone #4
Target Date -
Milestone #5
Target Date -
Milestone #6
Target Date
Team

Graduate Student Researcher
at National Taiwan University
Research area: Digital Circuits and Architectures
 Cortex-M3
Cortex-M3
![]() Accelerators
Accelerators
![]() Hardware design
Hardware design
![]() Standard Cell Libraries
Standard Cell Libraries
Submitted on
Comments
External I/O interface
Can you please expand on the External I/O interface implementation.
Kind regards,
John.
Details of AHB bus infrastructure
Hi,
Could you provide a little more detail on the AHB bus infrastructure? You say that low-latency is an important aspect of the application and I was wondering if you have chosen a specific interconnect IP to support this requirement.
John
Dear John, Thanks for your…
Dear John,
Thanks for your question. In this work, the 32-bit AHB-Lite bus infrastructure are chosen. This choice was based on it is inherently compatible with the open-source ARM Cortex-M3 processor implementation we employ. Within our system, the MCU facilitates the transfer of input/output data between the system memory and the accelerator. The choice of the AHB-Lite bus infrastructure aligns with our design specification. This is because the latency of the trajectory optimization algorithm primarily depends on the computing resources rather than the system bandwidth.
However, we acknowledge that changing to a faster bus infrastrucutre with the integration of a DMA engine is able to reduce the workload of the MCU. This would allow the MCU to handle the additional tasks concurrently.
Integration of a DMA engine
We have now taped out two designs using the NanoSoC reference design, one with the DMA 350 and one with the DMA 230 ip.
Integration of a DMA engine
Here are the two projects that use the nanosoc reference design that have been verified through to tape out and have ASICs operational in the test board.
Fast-kNN: A hardware implementation of a k-Nearest-Neighbours classifier for accelerated inference by Epifanios Baikas uses the DMA 230 .
Hell Fire SoC by Srimanth Tenneti uses the DMA 350.
Add new comment
To post a comment on this article, please log in to your account. New users can create an account.