Machine Learning
Research into Machine Learning and Artificial Intelligence is a very active field. This Machine Learning 'interest' area covers topics at the intersection of Machine Learning and SoC design from both the hardware and software perspective.
Research is creating a lot of new forms of model. How then to not only map these models efficiently into hardware execution but also how to make the process of doing it able to support rapid innovation while still be very efficient in use of resources?
Below is a generic overview of the support for ML/AI and there are specific sub-topics of this topic covering specific design environments and options. Please feel free to add and enhance this material.
Overview of design and deployment of ML/AI for the arm ecosystem.
In the design process, be that hardware, software or now ML/AI model development we use high level abstractions to allow iteration of the various design choices and constraints towards a design with acceptable trade off. The use of interpretive languages such as Python or tools like MATLAB® for rapid prototype of algorithms and model training allows rapid investigation of alternatives. In SoC Labs, these activities are associated with the initial design flow stages of Architectural and Behavioural design.
As the design process progresses it becomes more important to understand how the ML/AI model will be deployed for inference and optimised to run efficiently/timely on the available hardware resources.
The design process closes the gap between the actual hardware resources and the software system, including the ML/AI model, by translating the high level abstractions to intermediate representations and then low level primitives including of course instructions in the Arm Instruction Set Architecture ("ISA") to execute on the appropriate CPU. The software system is brought to execution via unique application code and pre-existing libraries as well as any operating system.
There are a growing catalogue of libraries to assist in the deployment of ML/AI models. If our target hardware has significant resources, a full operating system such as Linux, our deployment environment can be close to the model learning environment, eg. using various Python libraries, etc.
If our hardware target has limited resources then we need to close the gap. In the arm ecosystem a core library is CMSIS-NN which has different implementations of core ML/AI functions (that can be described by intermediate representations) depending on the ISA capabilities of the target Cortex-M processor. Any ML/AI model needs to be translated from it's high level abstraction to use the CMSIS-NN library.
As the Arm ecosystem is widely used, many AI/ML tool chains have already done this. The various open source tool chains, some listed as sub-topics here, are aggregated together from various libraries. Some tool chains are being developed to bridge the gap between any arbitrary ML models and translate them to run on any arbitrary hardware.
As well as the software system execution on the CPU tool chains are also looking to bridge the gap between ML models and deployment on custom hardware accelerators. There are tools to translate ML models into hardware description languages as well as into CPU instructions.
Some parts of an application of AI/ML like convolutions have mathematical foundations that can take advantage of parallelism of custom acceleration that can take up the majority of the compute time via the CPU ISA implementation. Other aspects may require more procedural functions such as bounding box reduction in image processing. Arm has a range of generic ML/AI accelerator cores, the Ethos range, and the Vela compiler which translates the intermediate representation of a TensorFlow LiteRT model into either operations that can be accelerated by the Ethos-U microNPU or left unchanged for execution on the CPU using the CMSIS-NN library.
As already outlined the design task is made harder if we have very resource constrained target hardware. If there is no operating system such as Linux only a real time operating system or even bare metal, then the library choice is very limited. The AI/ML has to be translated to specific low level primitives.
Deployment options within SoC Labs for the arm ecosystem
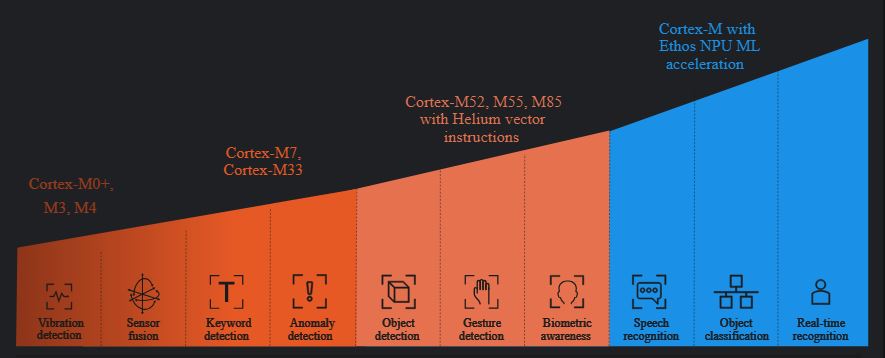
This diagram from the ML Developers Guide for Cortex-M Processors and Ethos-U NPU is helpful in visualising the types of ML application and the processor and reference design Arm suggest is appropriate.
Copyright © 1995-2024 Arm Limited (or its affiliates). All rights reserved
There are two reference designs that cover this M class space of applications.
Entry: nanoSoC, silicon proven. This is an M0 processor reference. There are a number of projects looking at vibration data and sensor applications within the community. nanoSoC is a bare-metal microcontroller which could execute the CMSIS-NN baseline profile for ISA without Single Instruction Multiple Data(SIMD). nanoSoC has been designed to support research into new custom accelerator core functions. These offload the AI/ML work to custom hardware driven by direct DMA transfers across the bus.
Mid range: milliSoC, in concept. milliSoC is targeting low latency applications and is expected to run a real time operating system and use low level C/assembly libraries to support the software system, including the AI/ML model. There is also the TSRI Arm Cortex-M55 AIoT SoC Design Platform utilising the Corstone 300 SoC infrastructure.
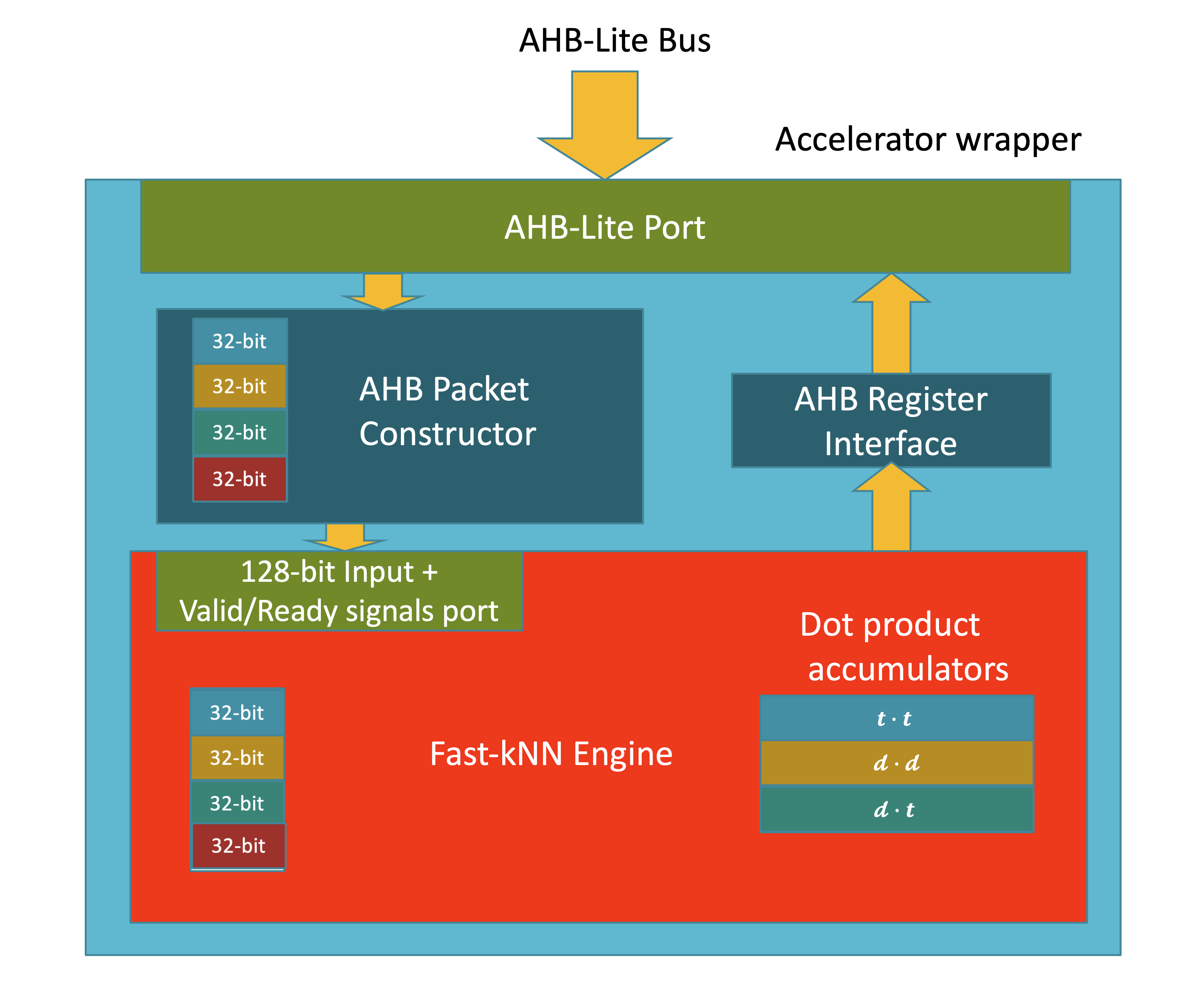
Choosing a target SoC reference design is not as simple as the above diagram suggests, for example the Fast-kNN project implemented Object classification on nanoSoC using the k-Nearest-Neighbours classifier and simple images of the Fashion-MNIST dataset. The simple grey scale images and efficeint classifier allow a simpler SoC to be utilised. High volume data, low latency sensing would need a larger SoC design. Keyword detection is a subset of Speech recognition. The difference is keyword detection usually using a very simple subset of a language, leading to a much smaller model which in turn leads to a smaller memory transfer issues and compute demand.
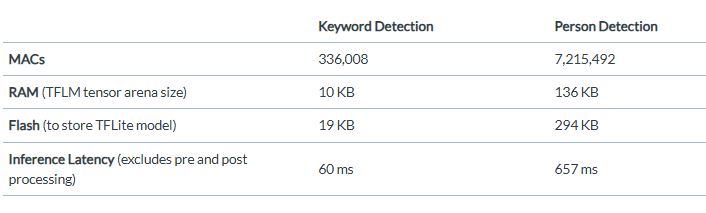
In this Arm community article on embedded ML the following table illustrated the different resources needed for keyword detection and person (object detection) using quantised 8 bit models and an M4 based processor.
Beyond M class:
High end: megaSoC, in design. This is a A class processor design, using the Corstone 1000 infrastructure. megaSoC is in design and is expected to run a full Linux OS which would support the use directly of python libraries. Projects looking at real time video analysis are using this platform.
ML Frameworks
There are a number of AI/ML frameworks under development. Some are described in this section along with specific material on Arm based implementations within these frameworks.
A number of SoC Labs projects have looked to use hls4ml to develop their AI/ML model as this allows rapid iteration and then deployment to an FPGA environment like Xilink PYNQ. The challenge in moving to an ASIC tape out flow is that the python support, the PYNQ environment and the arm CPU of the PS component of the Xilink board all have to be replaced by low level physical RTL representations within the ASIC and their equivalent low level primitives in the software system.
Optimisation of framework models for Arm compute
x
Copyright © 1995-2024 Arm Limited (or its affiliates). All rights reserved
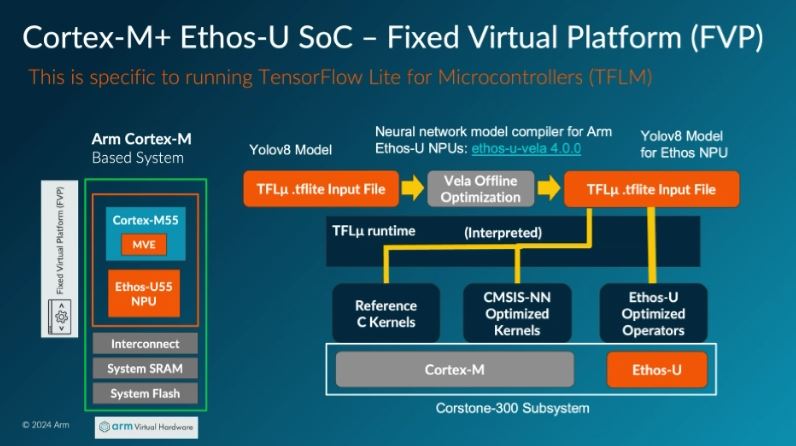
LiteRT is the new name for TensorFlow Lite (TFLite) which is a portable runtime for executing models from a number of AI/ML frameworks including TensorFlow. Without optimisation the runtime would use portable Reference C Kernels. Arm provides kernels optimised for it's processors in the CMSIS-NN library. Some operations can be highly optimised by execution within the Ethos-U accelerator. Velo takes a portable model and changes it to request the runtime to use the most efficient Arm compute infrastructure.
A baseline can be established by taking a model understanding how it can be effectively executed on the M55/U55 combination using a Fixed Virtual Platform as a simulation environment. In the same Arm community article on embedded ML the following table illustrated the different resources and latency for an optimised in unoptimised 8-bit quantized version of the BlazeFace (short-range) model used to identify the location of faces in an image.

Projects Using This Interest


Experts and Interested People
Members




Comments
Initial Material
Hi,
I have added some initial material on the Overview of design and deployment of ML/AI for the arm ecosystem and also two sub-topics on specific tool chains/environments, one on TensorFLow and specifically how it maps to the arm ecosystem and one on HLS4ML which is proving popular. If people want to comment or add an additional sub-topic on a tool chain/environment they are using that would be great.
We will aim to add more information on deployment of such tool chains/environments in combination with the developing SoC Labs reference designs as they develop. Please feel free to contribute as you feel able.
How can we make this more interesting?
Hi,
It seems quite a few of you have declared an interest in Machine Learning. What can we add to this section to make it more interesting? How can we get this thread started and more helpful to you?
Any feedback is really welcome.
John.
Add new comment
To post a comment on this article, please log in to your account. New users can create an account.