
Projects
Articles
Interests
Design Flow
Technology
Authored Comments
| Subject | Comment | Link to Comment |
|---|---|---|
| Analog front end team or processor team? |
Hello, I see in Milestone 4 of your project that you have an Analog front end team and a processor team. Which one have you been assigned to work on? We look forward to hearing from you. John. |
view |
| Welcome to SoC Labs |
Hello, Welcome to SoC Labs. It would be good to understand what you interests are in SoC Design and how we can help collaborate on things together. I see that another colleague has signed up, Duan Luong. Do you work together on the same projects? We look forward to hearing from you, John. |
view |
| Share your interest by adding them to your profile |
added any technology items or workflow stages to your profile to indicate things you are interested in or working on. It is simple to do, just edit your profile;
and add your interests;
The other way to add these is on each page that you find is interesting or part of your work you will find the action button to add it to your profile:
Having these should make it easier to find people to help and collaborate. |
view |
| Reviewing the project |
The nice thing about this project is that is looking to "Empower Scientific Edge Computing", trying to simply via abstraction the effort needed by the broader science community, such as physicists and other scientific disciplines (beyond our core computer engineering community), to deploy Neural Networks.
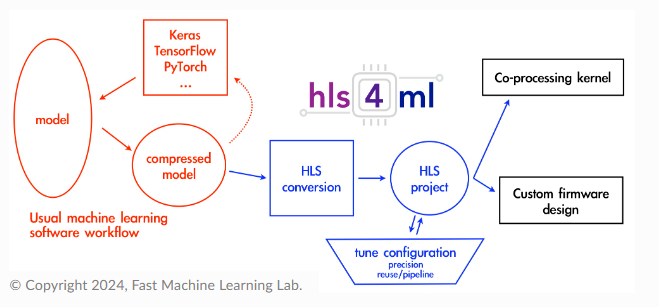 The CGAR4ML project also provide an abstraction layer in the design workflow and specific IP to allow more efficient deployment of models on FPGA and ASIC as a custom accelerator. 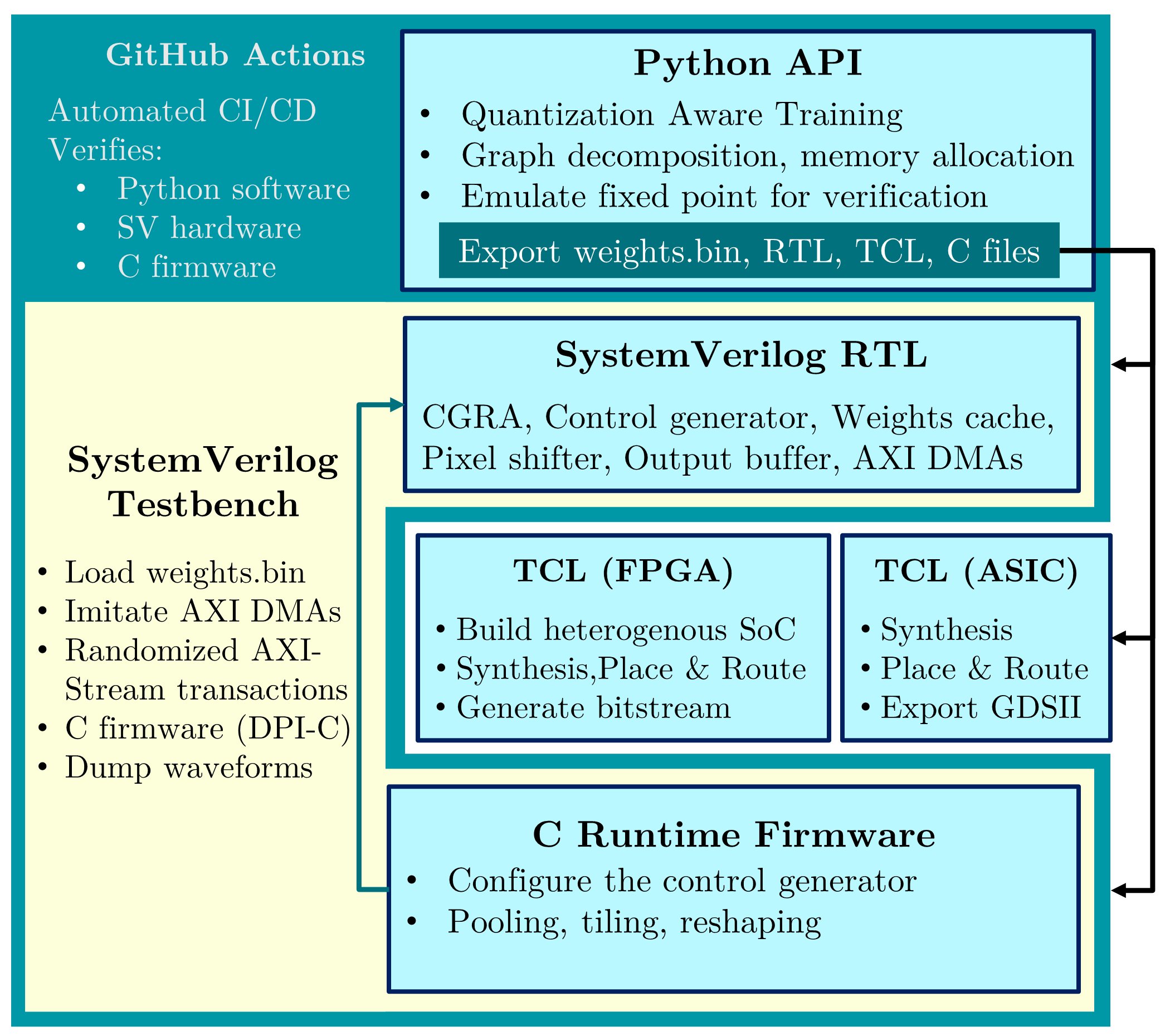 The challenge in this project has been the integration of a target reference design for a SoC implementation into the ASIC target while maintaining the alternate FPGA target. The Xilinx Vivado FPGA target uses an AXI interface with a number of DMA channels to move data into the custom accelerator engine. The nanosoc reference design is a simple M0 microcontroller based system for supporting research hardware such as a custom accelerators with an easy transition from FPGA to physical silicon ASIC. As an M0 based design it uses a simplified AMBA AHB bus design. The challenge then is to select appropriate IP blocks to bridge between the nanosoc design and the AXI based CGAR4ML custom accelerator. |
view |
| Bridging between nanosoc and the CGAR4ML custom accelerator |
The advantage to the research community of nanosoc reference design is the target design rational of a simple design that academics can understand and a low cost of implementation. The projects that have progressed through to tape out and demonstration using the low cost test board are;
The concept for this project was to attempt to also use the DMA 350 for data transfer into the CGAR4ML custom accelerator. The added design challenge being to maintain close compatibility with as much of the alternate FPGA IP. The initial nanosoc design had optional support for 1 or 2 Direct Memory Address controllers and two banks of DMA-accessible SRAM buffer space for concurrent expansion space for use by custom accelerators. To accommodate the CGAR4ML custom accelerator additional DMA channels are required and AHB / AXI interfacing. There are also considerations on how the use of interrupt handling for the DMA 350 on the M0 processor would operate compared to the firmware model within the CGAR4ML environment used to control the custom accelerator. |
view |
| Welcome to SoC Labs |
Hello, I see from the interests you have declared that you are interested in machine learning, accelerator design as well as A and M class processors. I am not sure what you are working on or if you are working with Kun-Chih (Jimmy) Chen and LIN, YU-CHI on the Smart Machine Box for Industrial IoT project? If you are you can add yourself to the project, simply click on the link; 
|
view |
| Using HLS4ML to generate models |
If you are still planning to use HLS4ML to generate a model you might be interested in one of last year's projects. I have added a few comments on what has been happening on Aba’s project by and the design challenges. Enhancing HLS4ML: Accelerating DNNs on FPGA and ASIC for Scientific Computing | Review Is my current overview of their project environment and Enhancing HLS4ML: Accelerating DNNs on FPGA and ASIC for Scientific Computing | Bridge Is an overview of the bridge issues from nanosoc to their custom accelerator
|
view |
| Welcome to SoC Labs |
Hello, I was just wondering which aspects of the project you were working on? We look forward to hearing from you. John. |
view |
| Tasks that are to run on the A53 CPU |
Hi, It would be great to know some details of the processes that are expected to run on the A53 class processor. Reading the project the tasking seems to be:
Have you decided on the software stack requirements needed for the A53 CPU? |
view |
| Off chip coordination and communication |
The original project looked to potentially use Ethernet connectivity to off load tasks to the cloud. I understand the project is looking at a simpler off chip strategy for now? Perhaps you can share where the project has got to with this aspect? |
view |
Add new comment
To post a comment on this article, please log in to your account. New users can create an account.