Competition 2024
Competition: Hardware Implementation
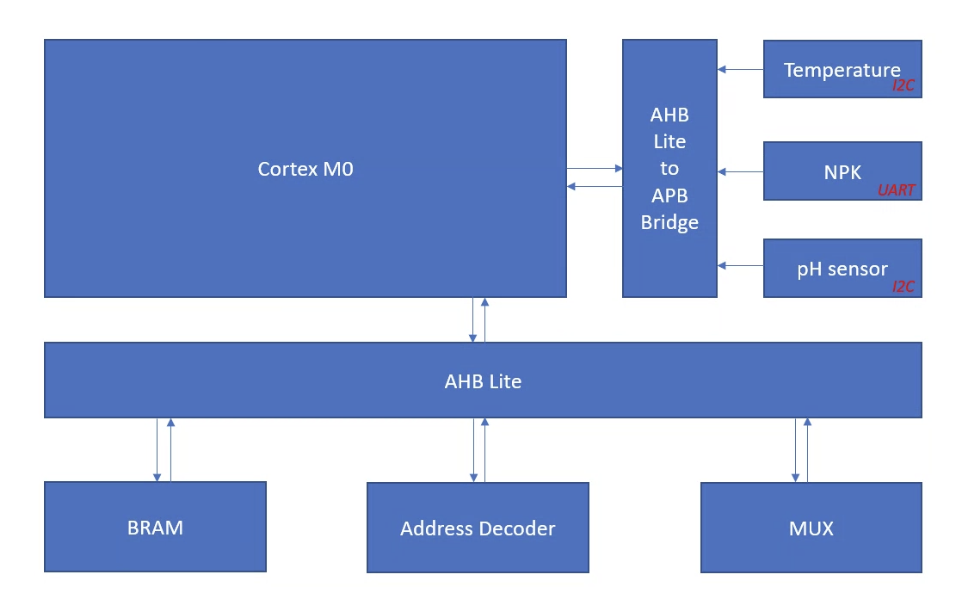
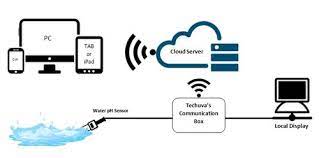
This project focuses on developing a plant growth monitoring system for space exploration missions using the ARM Cortex-M0 microcontroller core. The projects aim to develop a SOC based on ARM M0 core for interactive plant monitoring by interfacing AHB lite, GPIO, timers, and communication protocols such as UART, I2C, SPI, and co-processors. This project also proposes two co-processors for interactive plant monitoring and control. One AI co-processor for classification and prediction of plant and environmental data.


 AFOLAYAN, ABDULSAMAD
AFOLAYAN, ABDULSAMAD
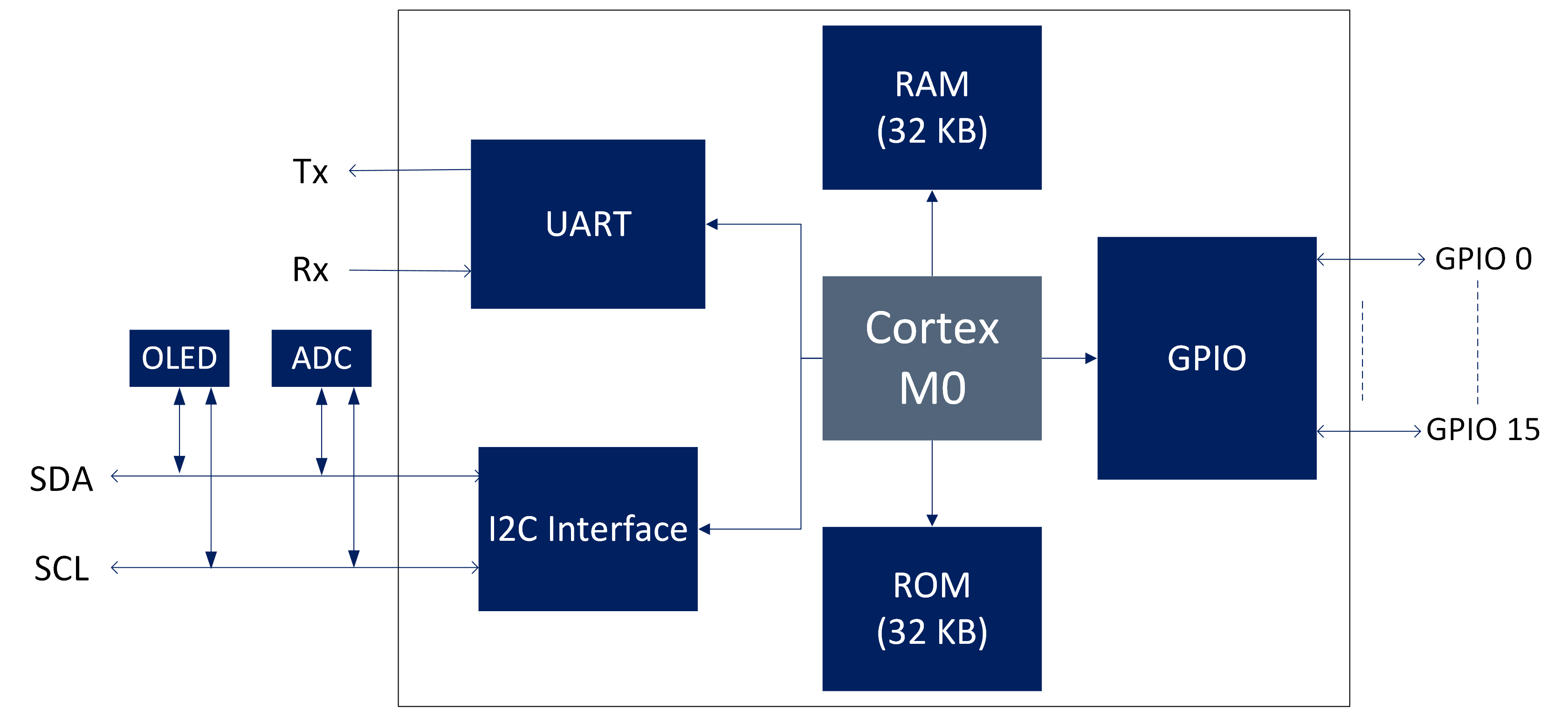
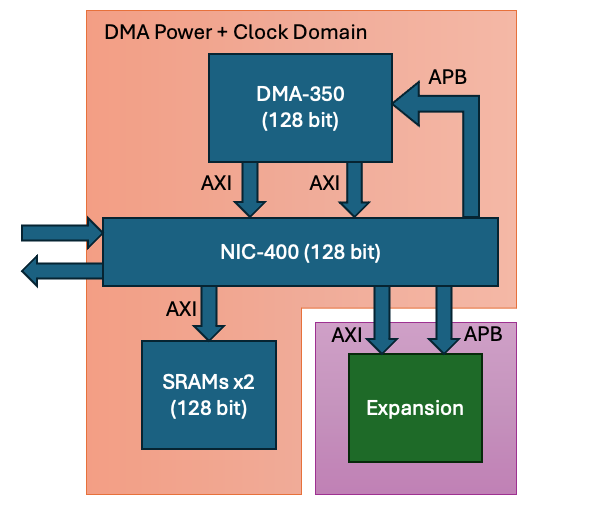
 Daniel Newbrook
Daniel Newbrook
 Ayodeji Oluwatope
Ayodeji Oluwatope



 rami hariri
rami hariri